En este post repasamos nuestra experiencia durante el proceso de optimización de la construcción de imágenes dentro de Kubernetes.
Veremos tanto la motivación de estos cambios (deja de ser posible utilizar Docker in Docker dentro de Kubernetes), así como la introducción de Kaniko como herramienta de construcción y cómo la implementación de una nueva librería de pipelines para nuestro Jenkins destapa los problemas de rendimiento que introdujo por culpa de un cacheo deficiente.
Los ejemplos de Dockerfiles que veremos son para microservicios con node, pero es fácilmente extrapolable a otras tipologías de proyecto que puedan sufrir los mismos problemas.
No nos entretengamos más. Al lío.
Un poco de historia:
Hace aproximadamente un año Kubernetes anunciaba que a partir de la versión 1.20 iba a deprecar Docker como motor para ejecutar los contenedores dentro de sus clusters.
Justifican este cambio debido a que les estaba suponiendo un importante esfuerzo mantener el soporte de Docker con el resto de componentes de la plataforma cuando ya existen otras alternativas a Docker más ligeras y que, además, encajan mejor con la arquitectura interna de Kubernetes. En este post de su blog explican muy bien los motivos de este cambio
La mayoría de las consecuencias son bastante transparentes de cara a quien quiera desplegar su imagen en un cluster de Kubernetes pero sí que contiene un importante cambio para los que quieran construir estas imágenes dentro del propio Kubernetes.
La manera más popular hasta la fecha era lo que se solía llamar Docker in Docker. Resumidamente, para poder ejecutar Docker desde dentro de un contenedor lo que se hacía era conectarse al demonio de Docker que estaba ejecutándose en la máquina padre y que fuera realmente este quien ejecutase los comandos. Esto funciona cuando la máquina padre también tiene Docker y eso es justo lo que iba a ser deprecado.
Por nuestra parte nos encontrábamos justo en el caso anterior: nuestros agentes de Jenkins se levantaban en un cluster de Kubernetes y necesitaban Docker para poder construir las imágenes de los productos.
Aún quedaba bastante tiempo para la versión 1.20 pero había que empezar a prepararse. Por una parte había que buscar una herramienta que pudiera construir imágenes desde dentro de un contenedor sin necesidad de que la máquina padre corriese Docker (en el artículo enlazado inicialmente hace referencia a varias opciones) y por otro lado sabíamos que iba a ser necesario optimizar los ficheros Dockerfile de los productos (nos centraremos en microservicios node que eran el 90% de lo que había desplegado en esos clusters de Kubernetes) puesto que no iba a ser lo mismo que las imágenes se construyesen en el demonio de Docker de un nodo completo de Kubernetes como lo solían hacer a que se construya en una pequeña imagen levantada dentro del cluster.
En paralelo al estudio de las distintas herramientas para atajar el problema de Docker in Docker se comenzó con la optimización de tiempos y dependencias en la construcción de imágenes. Tras varias alternativas y personas involucradas la que se acabó demostrando más eficiente fue una primera versión algo más completa de lo sugerido en esta respuesta de Stackoverflow:
##########################
# Cache-preserving image #
##########################
FROM alpine:3.14 AS deps
RUN apk --no-cache add jq
# prevent cache invalidation from changes in fields other than dependencies
COPY package.json .
COPY package-lock.json .
# override the current package version (arbitrarily set to 1.0.0) so it doesn't invalidate the build cache later
RUN (jq '{ dependencies, devDependencies }') < package.json > deps.json
RUN (jq '.version = "1.0.0"' | jq '.packages."".version = "1.0.0"') < package-lock.json > deps-lock.json
#################
# Builder image #
#################
FROM node:14.18.1-buster-slim as builder
ENV WORKING_DIR=/usr/src/app
WORKDIR ${WORKING_DIR}
COPY --from=deps deps.json ./package.json
COPY --from=deps deps-lock.json ./package-lock.json
RUN npm ci --production
COPY package.json .
####################
# Production image #
####################
FROM node:14.18.1-buster-slim
EXPOSE 9000
ENV WORKING_DIR=/usr/src/app
WORKDIR ${WORKING_DIR}
COPY --from=builder ${WORKING_DIR} ${WORKING_DIR}
COPY app ./app
CMD npm start
Como vemos se trata de un Dockerfile multistage. Estos habían sido introducidos hacía ya unos cuantos años, en 2017, en la 17.05 de Docker y consisten en crear capas temporales que no estarán en la imagen final para realizar acciones que luego sí aprovecharemos en la imagen definitiva.
Como vemos se trata de un Dockerfile multistage. Estos habían sido introducidos hacía ya unos cuantos años, en 2017, en la 17.05 de Docker y consisten en crear capas temporales que no estarán En este caso tenemos 3 stages, con el único fin de cachear lo máximo posible en el paso ‘npm ci –production’, que sería el comando más lento de nuestro Dockerfile con diferencia.
la imagen final para realizar acciones que luego sí aprovecharemos en la imagen definitiva.
En un primer stage (FROM alpine:3.14 AS deps) se crean unos ficheros temporales que contienen la misma información de dependencias que el package.json y el package-lock.json pero abstrayéndose de la información que no es relevante a la hora de instalar dependencias como el número de la versión, el nombre de nuestro propio proyecto o los scripts que pueda contener nuestro package.json.
Por ejemplo, para este package.json nuestro deps.json quedaría únicamente con los datos señalados en rojo:
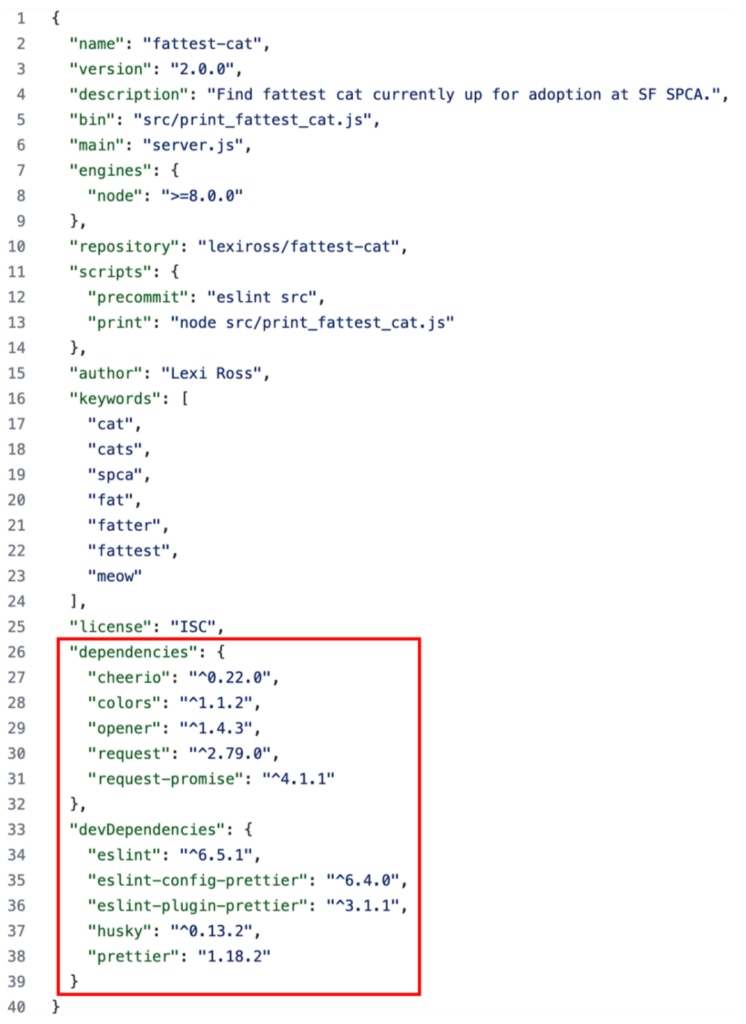
Así nos ahorramos que se rompa la caché, por ejemplo, cuando subamos la versión de nuestro proyecto que es una acción que pasará con bastante frecuencia.
En un segundo stage (FROM node:14.18.1-buster-slim as builder) se leen esos ficheros temporales que hemos generado antes y se usan para realizar un ‘npm ci –production’ que se espera que se cachee en la mayoría de las ocasiones. Estos dos ficheros no deberían cambiar casi nunca al haber eliminado la información que no es relevante para la caché. Posteriormente se copia el package.json original.
Y en el tercer y último stage (FROM node:14.18.1-buster-slim) preparamos el contenido definitivo de nuestra imagen a partir de lo generado en los stages anteriores. Con todo esto conseguimos unos tiempos bastante aceptables, al menos cuando en las construcciones se estaba utilizando la caché que era en la mayoría de las ocasiones.
Una vez desarrollado este modelo de optimización se decidió que la herramienta elegida para la construcción de imágenes fuera Kaniko.
De las herramientas disponibles era la que más se centraba en la seguridad, funcionaba con los mismos Dockerfile que teníamos por lo que la transición sería casi transparente para los equipos y además tenía a una empresa como Google detrás lo cual daba más confianza.
Tras algunas ejecuciones de prueba con nuestra la librería de pipelines se vió que los tiempos no aumentaban demasiado y que se seguía respetando la caché como lo había hecho Docker, así que se realizó el cambio definitivo para que todo el mundo pasara a construir sus imágenes con Kaniko, en su mayor parte con Dockerfiles basados en el que se ha mostrado arriba.
The issue:
Con este contexto pasó el tiempo sin mayores incidencias ni comentarios y tras un tiempo de desarrollo se liberó una nueva librería de pipelines para Jenkins.
Esta librería, a diferencia de la anterior, funciona con GitHub Flow. Esto en resumidas cuentas significa que todas las ramas nacen y mueren en la rama principal, ‘main’ de ahora en adelante, que las validaciones se realizan antes de mergear, cuando la MR/PR se abre o actualiza y que cada vez que se mergea se tagea la versión como final, se despliega en entornos previos y es susceptible de ser desplegada en producción en cualquier momento.
Esto significaba que cada rama que se crea lleva una nueva versión de nuestro producto.
Enseguida nos dimos cuenta que los tiempos de construcción de las imágenes habían aumentado considerablemente debido a que la inmensa mayoría de las ejecuciones no estaban cacheando el “npm ci”.
Tras analizar la incidencia en más profundidad se observó que, en realidad, en la antigua versión de la librería este cacheo tampoco estaba funcionando como debía. Esa librería funcionaba con un GitFlow tradicional en el que tenemos una rama de integración, la rama “develop”, que es la que siempre pasa la integración continua. Por tanto la integración continua se estaba lanzando sobre una rama estable y con la misma versión en el package.json durante un sprint entero, por tanto el número de ejecuciones sin caché era 1 o 2 cada dos semanas. Siendo así es normal que hubiera pasado completamente desapercibido.
Se realizaron múltiples pruebas, principalmente centradas en dos flags de Kaniko:
- ‘–reproducible’: sirve para eliminar timestamps de una ejecución y así hacer que dos ejecuciones en momentos distintos generen el mismo resultado.
- ‘–snapshotMode’: se utiliza para seleccionar qué utiliza Kaniko para comparar si dos ficheros son iguales y decidir, por tanto, si se puede o no utilizar la caché con ellos.
Lamentablemente en ningún caso conseguimos que se preservara la caché cuando cambiábamos el nombre o la versión de nuestro producto en el package.json, que era el objetivo principal del Dockerfile propuesto.
El ‘snapshotMode‘ menos restrictivo, si miramos la documentación, utiliza solo el atributo mtime. Esto significa que utilizamos la fecha de última modificación del fichero como manera de discernir si dos ficheros han cambiado y por tanto no nos vale la caché o si siguen siendo el mismo y sí que podemos usar la caché.
Visto esto probamos incluso a añadir un ‘touch -m —date‘ dentro del Dockerfile tras crear los ficheros temporales deps.json y deps-lock.json tal que así:
##########################
# Cache-preserving image #
##########################
FROM alpine:3.11 AS deps
RUN apk --no-cache add jq
# prevent cache invalidation from changes in fields other than dependencies
COPY package.json .
COPY package-lock.json .
# override the current package version (arbitrarily set to 1.0.0) so it doesn't invalidate the build cache later
RUN (jq '{ dependencies, devDependencies }') < package.json > deps.json
RUN (jq '.version = "1.0.0"' | jq '.packages."".version = "1.0.0"') < package-lock.json > deps-lock.json
RUN touch -m --date "2021-01-01" deps.json
RUN touch -m --date "2021-01-01" deps-lock.json
...
Para asegurarnos que los ficheros no solo eran los mismos, si no que además se lo pareciera a Kaniko y con todo esto el cacheo siguió sin funcionar como se esperaba.
The solution:
Tocaba dar un paso atrás y repensar.
Todo parece indicar que Kaniko por error está dando por hecho que los ficheros no son los mismos por el simple hecho de que ha sido el propio Kaniko el que los ha generado construyendo la imagen, aunque sea en otro FROM distinto de en el que se utilizan posteriormente.
Si este es el caso, quizá solo necesitamos crear estos ficheros antes de empezar a construir la imagen fuera del Dockerfile. Dado que estamos hablando de una librería de pipelines interna no nos cuesta nada realizar esta tarea sencilla antes de construir las imágenes y con eso disponibilizar los ficheros para que puedan ser utilizados por los Dockerfiles de los equipos.
Hacemos una pequeña prueba y bingo, si los ficheros temporales deps.json y deps-lock.json no los genera el propio Dockerfile cachea sin problemas, incluso cuando cambiamos la versión/nombre/scripts de nuestro proyecto y sin necesitar hacer el ‘touch -m –date’ en el pipeline siquiera.
A la vista de esto se hace evidente que el enfoque multistage de las imágenes ya no está justificado y, probablemente, lo único que haga sea añadir tiempo a nuestra construcción, así que seguimos simplificamos nuestro Dockerfile hasta dejarlo algo parecido a esto:
FROM node:14.18.1-buster-slim
ENV WORKING_DIR=/usr/src/app
WORKDIR ${WORKING_DIR}
EXPOSE 9000
COPY deps.json ./package.json
COPY deps-lock.json ./package-lock.json
RUN npm ci --production
COPY package.json .
COPY app ./app
CMD npm start
Con todos los cambios terminados, llega el momento de comparar:
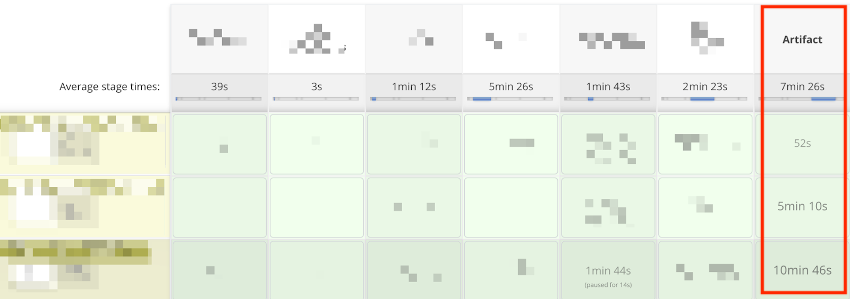
- 10 minutos con el Dockerfile multi-stage que mencionamos inicialmente que casi nunca cacheaba.
- 5 minutos con el Dockerfile nuevo sin tener caché lista aún.
- 52 segundos con el Dockerfile nuevo con caché disponible.
Como podemos ver la mejora es más que evidente: pasamos de un tiempo medio de construcción de cerca de 10 minutos (inmensa mayoría de ejecuciones sin caché) a un tiempo medio cercano a un minuto (solo fallará la caché cuando actualicemos dependencias, poco a menudo), 10 veces más rápido que lo que teníamos y sin necesidad de sobrediseñar la solución.
Esto tiene una parte negativa evidente que no podemos obviar: tenemos en nuestros repositorios un Dockerfile que depende de ficheros externos que no están en nuestro repositorio, esto implica que si alguien quiere construir la imagen en local tendrá que generar esos ficheros por si mismo.
Lo bueno es que para construir en local, si no te preocupa el tiempo tanto como en una integración continua donde se va a estar lanzando constantemente, puedes simplemente copiar tus ficheros package.json y package-lock.json y cambiarles el nombre y eso sería más que suficiente para construir, no necesitas ni saber cómo se generan esos ficheros durante la integración continua ni con qué fin, por lo que el acoplamiento entre nuestro Dockerfile y nuestra integración continua, si bien existe, es realmente bajo.
Lecciones aprendidas:
- No des cosas por hecho: aunque el error no tuviera mucho impacto por el GitFlow que se seguía, estuvo ahí mucho tiempo pasando inadvertido, se podría haber detectado antes si se hubieran hecho pruebas más exhaustivas.
- No obcecarse: las soluciones no siempre nos las tienen que dar herramientas, puede que tengan issues o que simplemente no se ajusten al problema que necesitamos resolver, a veces hay que ser imaginativo y mirar los problemas desde una perspectiva más amplia.
- Keep it simple: soluciones como los Dockerfiles multistage pueden resultar muy útiles y resolver problemas que de otra forma no tendrían solución pero tienen un coste que hay que tener en consideración y no se deben usar a la ligera.