En nuestro día a día lidiamos con una gran cantidad de información sensible, muchas veces incluso sin darnos cuenta: usuarios, contraseñas, claves privadas, tokens, o simplemente URLs o direcciones IP que no tienen por qué ser de dominio público. Toda esta información podemos agruparla bajo el concepto de secretos.
De todos los sitios en los que podemos encontrarnos estos secretos, hay uno especialmente sensible y a menudo difícil de detectar: los repositorios de código. En este artículo hablaremos específicamente de los de git, pero el concepto es extensible a otros.
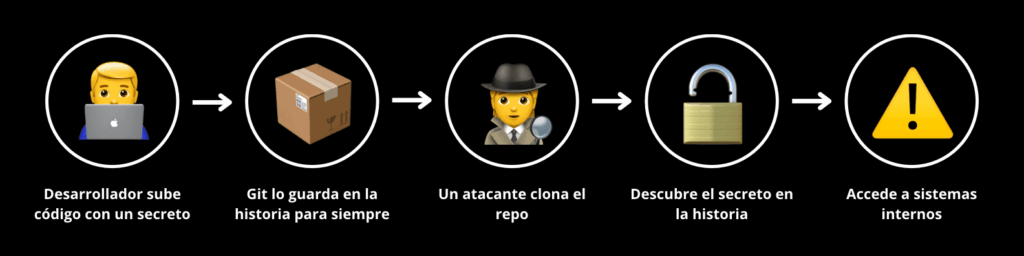
Un repositorio de código no guarda ficheros como cualquier otro sistema de almacenamiento, sino que guarda los cambios entre un commit y el siguiente, y además los guarda para siempre. Esto significa que, si por error se llega a subir un secreto a un repositorio, el borrarlo y hacer un nuevo commit no resuelve el problema. Lo único que consigue es esconder debajo de la alfombra una vulnerabilidad que sigue estando ahí: el secreto va a seguir visible y accesible en la historia de Git.
Cuando hablamos de un solo repositorio de código o de grupos de trabajo pequeños, puede ser relativamente manejable, pero en cuanto crece el tamaño de nuestra organización y el número de personas colaborando en nuestros proyectos, las probabilidades de que estemos compartiendo contraseñas con el mundo aumentan considerablemente, hasta prácticamente garantizar que habrá secretos en nuestros repositorios.
Podemos pensar que nuestros repositorios son privados, o que están detrás de una VPN, pero nunca sabemos quién tiene —o tendrá— acceso a esos repositorios. Porque, recordemos: una vez un secreto está en Git, va a estar ahí para siempre, y cualquiera que descargue el repositorio con ese secreto tendrá esa historia en su propio ordenador, siempre disponible.
Y, por supuesto, tampoco sabemos si parte de ese código o esa historia de Git —que ya sabemos que no podemos controlar— alguna vez va a salir de la organización, ya sea de manera intencionada o no.
¿Debo entrar en pánico ya?
Ahora que somos conscientes del potencial riesgo de seguridad que todos tenemos, viene lo interesante: ¿qué hacemos para remediarlo? En este post nos vamos a centrar en lo primero que necesitamos hacer: levantar la alfombra y ver qué hay ahí debajo…

Si nos ponemos a buscar por internet, veremos que hay una gran variedad de herramientas de código abierto disponibles. Además, comprobaremos que en los últimos años la mayoría de los servicios de repositorios de código han comenzado a añadir sus propias soluciones de detección de secretos, bien sea usando analizadores externos como Gitlab con gitleaks, o bien desarrollando sus soluciones privadas como Github o Bitbucket.
El problema es que no todas están disponibles de manera gratuita y, además, suelen estar disponibles solo dentro de las integraciones continuas de sus servicios, lo cual implica dos cosas:
- Si usamos un servidor de integración continua externo, como Jenkins por ejemplo, no podemos hacer uso de ellas.
- Solo se analizarán los repositorios que pasen por la integración continua, es decir, los que estén siendo desarrollados activamente. Pero eso no significa que no vaya a haber secretos en repositorios discontinuados, con muy bajo mantenimiento, o que simplemente no tienen una IC activada.
Por estas razones hemos decidido hablar en este post de una herramienta que no solo es de código abierto y que, por tanto, podremos usar dónde y cuándo queramos, sino que nos aporta facilidades para analizar grandes grupos de repositorios con un solo comando, algo especialmente útil cuando vamos a buscar secretos por primera vez, o si simplemente llevamos tiempo sin hacerlo y no podemos garantizar, mediante la integración continua, que todos los repositorios de nuestra organización estén siguiendo una política de detección de secretos suficiente.
TruffleHog permite escanear cualquier repositorio, en cualquier momento, sin depender de CI/CD o servicios de terceros.
¿Qué es truffleHog y cómo funciona?
Nosotros conocimos Trufflehog hace años, a raíz de un artículo de GitLab en el que la nombraban como una de las herramientas en las que habían basado su propio detector de secretos. Tras probarla, nos pareció de las herramientas más completas del momento.
Es verdad que no estaba mantenida demasiado activamente, pero era la que mejores resultados obtenía (a pesar de un gran número de falsos positivos) y, sobre todo, con la que más fácil era trabajar, puesto que tenía varios reporters, lo cual facilitaba el posterior procesamiento de los resultados.
Hace unos años se formó una organización para comercializar una solución que envuelve a TruffleHog, con otros analizadores, ejecuciones programadas y dashboards. Esto, en la parte que nos ocupa, ha revitalizado mucho el desarrollo de la parte open source, que se ha reescrito por completo en Go, manteniendo compatibilidad con los comandos originales y añadiendo nuevas funcionalidades.
Así que vamos a dar un pequeño repaso a todo lo que nos ofrece y a enseñar un ejemplo de uso para sacarle partido.
Modos de ejecución
Trufflehog tiene distintos analizadores, cada uno de ellos con sus propias opciones de configuración, además de las opciones comunes. Veamos resumidamente algunos de ellos:
Trufflehog git
El comando principal y el que más opciones tiene, funciona tanto con repositorios remotos (http o ssh) como locales. Tiene opciones de análisis muy útiles como excluir ciertos ficheros del análisis (ficheros autogenerados o de terceros) o analizar sólo desde cierto commit para cuándo queremos lanzarlo en una integración continua y solo queremos validar el incremento.
Trufflehog gitlab
Si le proveemos de un token de acceso podemos escanear o bien una lista de repositorios o bien directamente todos los repositorios a los que tenga acceso ese token. Muy útil para lanzar análisis a gran escala, pero carece de las opciones para afinar la búsqueda del comando ‘trufflehog git’.
Trufflehog github
Similar al de Gitlab pero no exactamente igual. Con un token de acceso podemos escanear una lista de repositorios o bien una lista de organizaciones.
Trufflehog filesystem
Simplemente a partir de un path local analiza todo lo que haya debajo de él.
Trufflehog s3
A partir de unas credenciales y el nombre de un bucket de s3 nos analiza todo lo que contenga.
Trufflehog syslog
Con una dirección web de la que leer los syslogs y la opción de pasarle los certificados si fueran necesarios te analiza los syslogs.
El fin de todos los comandos es el mismo: buscar secretos que se puedan estar filtrando. En los tres últimos casos, la búsqueda es sencillamente sobre ficheros, mientras que en los tres primeros, que son los que más nos interesan, es sobre toda la historia de git de los repositorios a los que haga referencia.
Los comandos de GitLab y GitHub son útiles para lanzar un primer análisis rápido de todo y ver de un vistazo (en breve veremos a qué se refiere eso de “un vistazo”) si hay algo de lo que debamos preocuparnos de manera urgente. Pero cuando queramos hacer un análisis más en profundidad y pormenorizado, muy probablemente nos sea más útil el comando de git, ya que las opciones de excluir ficheros o lanzar a partir de cierto commit nos van a ser muy interesantes a la hora de filtrar los resultados y encontrar los que nos interesen.
Credential verification
Uno de los principales problemas de las herramientas de detección de secretos son los falsos positivos. Si queremos que nos muestre cualquier cosa que pueda ser un secreto, es fácil que acabemos teniendo demasiados falsos positivos y nos cueste encontrar las que son vulnerabilidades reales. Y si, por el contrario, intentamos evitar esos falsos positivos, podemos poner en riesgo que haya secretos sin detectar, lo cual, siendo ese el único fin de estas herramientas, sería bastante desafortunado.
Conscientes de esto, en TruffleHog han decidido tomar un enfoque intermedio. Por defecto, siguen mostrando todo lo que creen que podría ser una credencial, con su correspondiente ración de falsos positivos, para que puedas revisarlo sin prisa. Pero han implementado un sistema de verificación de credenciales, por el cual tratan de validar el secreto contra el servicio al que creen que pertenece. Por ejemplo, si algo parece una clave de AWS, preguntan a AWS si se trata de una credencial válida.
Todo se entiende mejor con ejemplos así que veamos un ejemplo de resultado verificado:

TruffleHog ha encontrado un token que parece ser de GitHub, ha probado a tratar de hacer una petición a GitHub con ese token y, como ha funcionado, podemos estar seguros de que tenemos un token válido expuesto en la historia de nuestro repositorio, que deberíamos revocar a la mayor brevedad posible.
Por otro lado en esta otra imágen tenemos un resultado sin verificar:
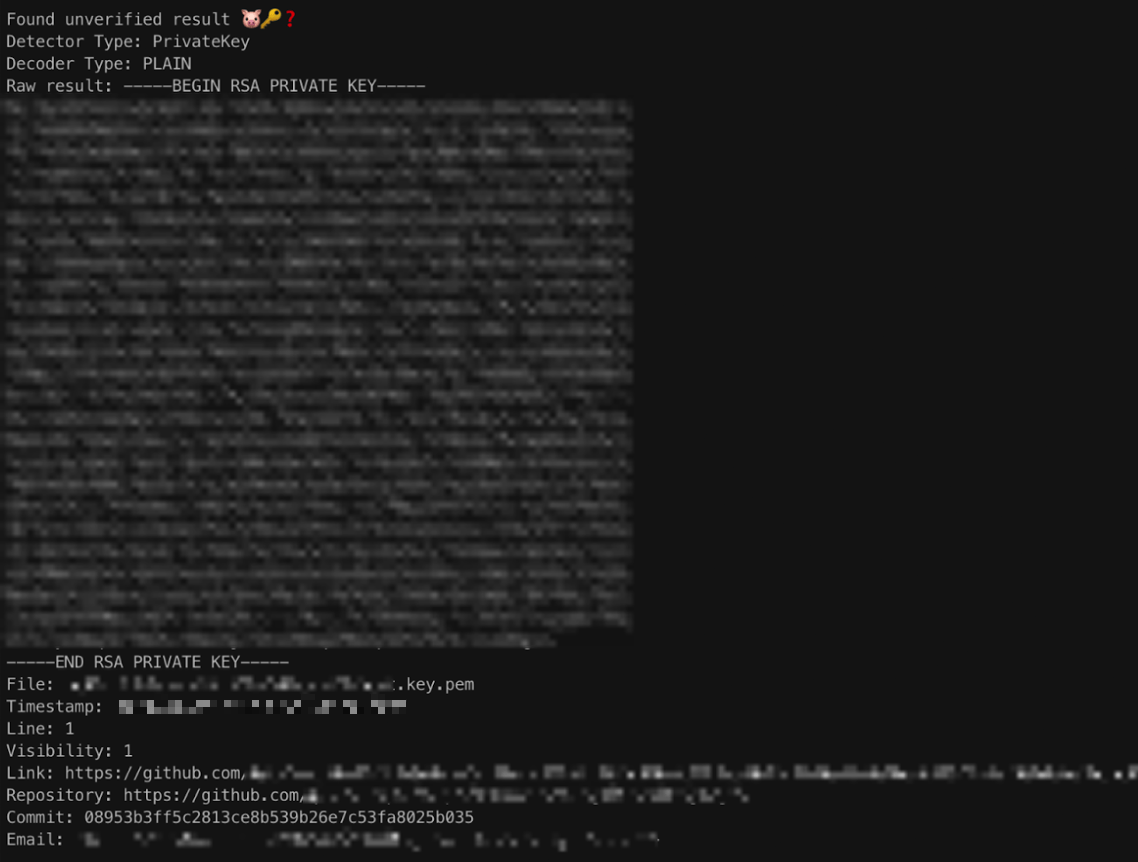
TruffleHog, para el caso de las claves privadas, tiene un listado inmenso de claves públicas conocidas (aquí explican de dónde sale), y lo que hace es extraer la clave pública a partir de la privada que ha encontrado en el análisis y comprobar si coincide con alguna de su base de datos.
Que no esté en ese listado y, por tanto, el secreto aparezca como no verificado —como en este caso— no es en absoluto una garantía de que no se esté usando, y habría que revisar el resultado igualmente, aunque no con la misma urgencia con la que deberíamos haber revisado un resultado verificado.
Análisis de secretos
Vamos a distinguir en este punto dos tipos de escaneos de secretos:
- Los que lanzaríamos en una integración continua, que se ejecutarían sobre un incremento,
- Y los análisis más pormenorizados que podríamos lanzar sobre un grupo grande de repositorios o sobre repositorios individuales sin integración continua, y que se realizarían sobre toda la historia de Git.
Escaneo en IC
Cuando estamos lanzando un análisis en la integración continua, nos interesan principalmente dos cosas:
- No bloquear las builds a no ser que de verdad haya un problema (no queremos que un falso positivo nos pare la build a diario).
- Analizar únicamente el código nuevo.
Con esto en mente, un posible comando para lanzar en un flujo de merge request / pull request a master sería:
last_commit=$(git rev-list --no-merges -n 1 master)
trufflehog git file://. --only-verified --fail --since-commit=$last_commit –branch=feature/my-feature
last_commit=$(git rev-list --no-merges -n 1 master)
├── # El análisis de Trufflehog se realiza únicamente sobre commits que no corresponden a un merge para no duplicar resultados.
└── # Debemos asegurarnos de que el commit desde el que le decimos que inicie el análisis no corresponde a un commit de merge.
trufflehog git
└── # Vamos a analizar un repositorio de git, lo que nos interesa son los commits, no los ficheros que hay descargados ahora mismo.
file://.
├── # El repositorio que queremos analizar, puesto que estamos en una integración continua,
└── #ya lo tenemos descargado y actualizado, por lo que será más eficiente utilizar ese que apuntar al repositorio remoto.
--only-verified
└── # Muestra solo los resultados verificados, los que estamos completamente convencidos de que son un secreto que se está filtrando.
--fail
└── # Si encuentra cualquier resultado (verificado, por el flag anterior), el comando devuelve un código de error y detiene la build.
--since-commit=$last_commit
└── # Solo queremos analizar los commits posteriores al último commit de la rama contra la que queremos mergear, en este caso master.
--branch=feature/my-feature
└── # Para que analice todos los commits que hemos añadido en nuestra rama, la que estamos tratando de mergear en master.
Ésto se podría ampliar y afinar, por supuesto, pero tan solo con esas dos líneas podríamos tener una garantía de que no estamos filtrando secretos por accidente, al menos no secretos fácilmente explotables por terceras partes (como los que Trufflehog es capaz de verificar).
Escaneo en profundidad
A diferencia del análisis durante la integración continua, en este caso sí queremos analizar la historia completa de Git, probablemente de más de un repositorio, y no nos importa analizar manualmente los resultados para descartar falsos positivos. El objetivo aquí es asegurarnos de que no nos hemos pasado nada por alto.
Además, como vamos a querer analizar manualmente los resultados, el formato de presentación de resultados por defecto (por consola) no parece el más adecuado. Veamos varios ejemplos de cómo realizar estos análisis tanto con el comando de Git como con los de GitHub y GitLab, que aunque menos flexibles, nos pueden facilitar la vida:
trufflehog github --token=YOUR_TOKEN --org=YOUR_ORGANIZATION --json (--no-verification) > trufflehog.json
trufflehog github
├── # Utilizamos el analizador de Github, recorre toda la historia de git igualmente pero facilita recorrer todos tus repositorios.
--token=YOUR_TOKEN
├── # Tu token de acceso a Github, puesto que no vas a lanzar este comando todos los días,
└── # sería una buena idea que sea un token generado exclusivamente para esto y con una expiración lo más breve posible.
--org=YOUR_ORG
├── # La organización que queremos escanear dentro de Github, podemos repetir este flag tantas veces como queramos en caso de que tengamos más de una.
--json
├── # Para que nos muestre las vulnerabilidades en json, y de esta forma podamos procesarlas y validarlas con mayor facilidad.
(--no-verification)
├── # Si no es la primera vez que pasamos este análisis y tenemos ciertas garantías mediante la IC de que no habrá resultados verificados
├── # podemos añadir este flag para acelerar el análisis, puesto que si el número de repositorios a analizar es muy grande
└── # el proceso de verificación puede añadir bastante tiempo a nuestro análisis.
> trufflehog.json
└── # Guardamos los posibles secretos desvelados en un json para poder procesarlos más adelante en lugar de dejar que se pierdan en nuestra terminal.
trufflehog gitlab --token=YOUR_TOKEN --json (--no-verification) > trufflehog.json
trufflehog gitlab
├── # Utilizamos el analizador de Gitlab, recorre toda la historia de git igualmente pero facilita recorrer todos tus repositorios.
--token=YOUR_TOKEN
├── # Tu token de acceso a Github, puesto que no vas a lanzar este comando todos los días,
└── # sería una buena idea que sea un token generado exclusivamente para esto y con una expiración lo más breve posible.
--json
├── # Para que nos muestre las vulnerabilidades en json, y de esta forma podamos procesarlas y validarlas con mayor facilidad.
(--no-verification)
├── # Si no es la primera vez que pasamos este análisis y tenemos ciertas garantías mediante la IC de que no habrá resultados verificados
├── # podemos añadir este flag para acelerar el análisis, puesto que si el número de repositorios a analizar es muy grande
└── # el proceso de verificación puede añadir bastante tiempo a nuestro análisis.
> trufflehog.json
└── # Guardamos los posibles secretos desvelados en un json para poder procesarlos más adelante en lugar de dejar que se pierdan en nuestra terminal.
while IFS= read -r repository; do
echo $repository
name=$(basename $repository .git)
trufflehog git $repository --exclude-paths=exclude.txt --json (--no-verification) > $name.json
done < repositories.txt
while IFS … done < repositories.txt
├── # Recorremos un fichero txt que contiene un repositorio de código por línea,
└── # de esta sencilla manera compensamos la limitación de este comando de Trufflehog que acepta un único repositorio.
echo $repository
├── # El comando que vamos a ejecutar no tiene salida por consola y puede tardar bastante tiempo en ejecutarse
└── # dependiendo de cuántos repositorios le pasemos, así que es útil tener una idea de por dónde va la ejecución.
name=$(basename $repository .git)
├── # Nos quedamos con el nombre del repositorio para más adelante.
trufflehog git
├── # Utilizamos el analizador de repositorios git, funciona tanto para repositorios locales como remotos por http y ssh,
├── # en este caso lo más cómodo es que se trate de repositorios por ssh “git@git….:....git”
└── # puesto que con solo tener configurada la clave privada de un usuario con permisos suficientes todo el script se ejecutará sin interrupciones.
--exclude-paths=exclude.txt
├── # Este comando tiene la ventaja de que nos permite excluir rutas potencialmente conflictivas,
├── # cuando vamos a analizar un gran número de repositorios puede pasar que alguien haya subido por accidente un node_modules
├── # o una carpeta con compilados, lo cual puede incrementar bastante el tiempo de ejecución de nuestro script.
├── # Pasándole este exclude.txt con todos esos paths conflictivos nos aseguramos de que no perdemos el tiempo analizando
└── # ficheros y rutas que no han sido escritos por nosotros.
--json
├── # Para que nos muestre las vulnerabilidades en json, y de esta forma podamos procesarlas y validarlas con mayor facilidad.
(--no-verification)
├── # Si no es la primera vez que pasamos este análisis y tenemos ciertas garantías mediante la IC de que no habrá resultados verificados
├── # podemos añadir este flag para acelerar el análisis, puesto que si el número de repositorios a analizar es muy grande
└── # el proceso de verificación puede añadir bastante tiempo a nuestro análisis.
> $name.json
└── # Guardamos los posibles secretos desvelados por cada repositorio en un json con su nombre para luego tenerlos un poco más ordenados.
Todas estas opciones pretenden ser únicamente un punto de partida para conseguir nuestros resultados en un formato fácil de procesar. Una vez que tengamos los resultados, tenemos que decidir qué queremos hacer con ellos:
- Podemos hacer algún tipo de procesado previo de estos datos para, por ejemplo, dar prioridad a cierto tipo de analizadores o a ciertos grupos de repositorios.
- También podríamos generar estadísticas rápidamente procesando el JSON con jq para saber, antes de analizar los datos en profundidad, qué valores llaman más la atención y que tal vez debamos revisar primero.
- O si simplemente queremos pasarlos a un Excel con un json2csv para revisarlos a mano con más facilidad.
Como podemos ver, una vez tengamos los datos, hay numerosas formas de ampliar nuestros scripts para ajustarlos a las inevitables particularidades de nuestras organizaciones y sacar el máximo partido de esta herramienta. Pero eso ya dependerá de cada uno, y esperamos que con los ejemplos de este artículo tengamos una buena base para empezar.
¿Y ahora qué hago?
Llegamos a la recta final. Hemos conseguido procesar de manera cómoda nuestros resultados, y hemos descubierto que efectivamente tenemos secretos accesibles en nuestros repositorios, o bien nuestra IC nos ha parado un pipeline porque ha detectado un secreto válido.
Ya hemos observado con terror que, aunque borremos el secreto de nuestro repositorio, va a permanecer en la historia de git, así que quizás alguno esté pensando que, aunque poco recomendable, git nos permite reescribir su historia. Por ejemplo, haciendo un squash de los commits entre el que añadió el secreto al repositorio y el commit que lo borra, haciendo de esta forma que el secreto filtrado desaparezca también de la historia de git. Pero esto no es más que una forma de esconder mejor el problema, no una solución.
Incluso para esos secretos que hemos detectado en la IC y que llevan muy poco tiempo en nuestros repositorios, y ya no hablemos de los que hemos descubierto en un análisis en profundidad que pueden llevar años ahí, no podemos saber cuánta gente ha tenido acceso a ellos durante el tiempo que han estado públicos. Por lo que la única solución es rotar esa credencial, revocar el acceso a todos los sitios que diera acceso ese secreto y generar nuevas credenciales para el que las necesite.
Y no queremos cerrar este post sin un consejo: no hace falta esperar a que se filtren nuestros secretos para rotarlos. Si seguimos la buena práctica de rotar secretos con cierta periodicidad, podemos estar ahorrándonos gran parte de estos problemas, incluso antes de haberlos detectado.